
Architecture of Complex Video Analytics Applications
The goal of a video analytics system or application is to generate insights from an observed video stream. In a video analytics system, a continuous stream of video frames is the input which might be originated from various sources, e.g., web cam, mobile camera, Kinect sensor, security camera, video file etc. The output could be one or more video frames per input frame or some data representing insights or perception of the observed scene. Depending on the application, the output video frames might be annotated. For instance, in a face detection application (typically available in cameras), detected faces are highlighted with rectangle; in an object detection system (surveillance applications), moving objects are highlighted and might be annotated with object class such as person, group, car etc.

Inside a video analytics system, one or more processing tasks are performed by various processing components. A processing component enables a particular machine vision capability (low or high level). Usually more than one processing component is used to develop a system for generating a particular kind of insight (e.g., abnormal run detection, face recognition etc.). The application of such single-insight system is limited to the operating environments where we are interested for a specific kind of insight only.
If we are interested in all possible insights, how can we enable such capabilities using a single video analytics system? Does the availability of all possible processing components determine the overall analytics capability? For instance, if we develop a video analytics system with components for all possible machine vision tasks (e.g., face detection, gesture recognition, object detection, event detection, tracking etc.), will it be able to operate reliably in real-time? Yes, it is possible to develop such a real-time video analytics system equipped with all possible components. The hypothesis here is that not all capabilities or components need to be enabled at the same time. A mature human brain has hundreds of skills/capabilities; however, does he/she need to apply them at the same time? A concrete example: in an indoor monitoring system, both face recognition and gesture recognition are enabled. In the face of emergency (e.g., fire) abnormal run detection needs to be enabled; however, how relevant are the face and gesture recognition?
In short, in any context only a subset of the available capabilities is essential. If the dynamics of the context changes, we will need a different subset of capabilities, but not all. One solution to this problem is to have a dynamic architecture for the video analytics system that can dynamically enable/disable capabilities based on the dynamics of the context. Subsequent paragraphs briefly explain some preliminary concepts that are essential for the design and understanding of a dynamic video analytics architecture.
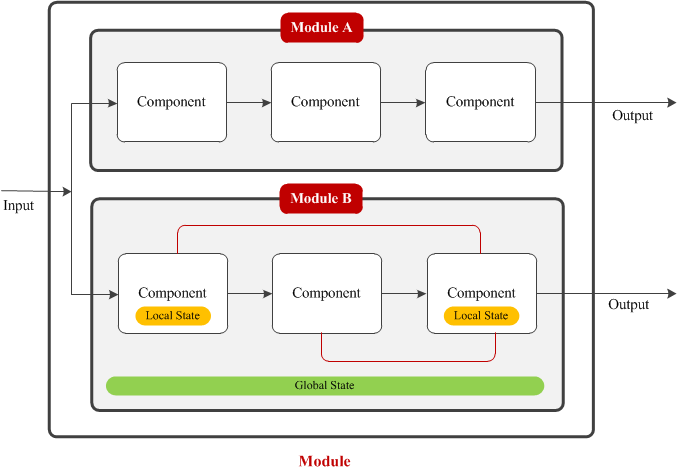
Component
A component represents a single processing unit or processing task, e.g., face detection, edge detection etc. The corresponding algorithm of these types of tasks works on a single frame image and produce the output image without any other dependencies.

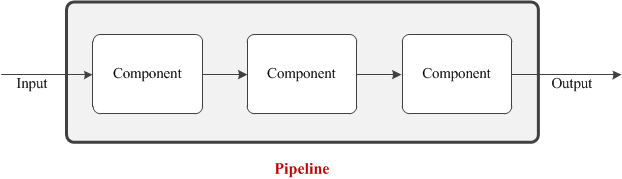
Pipeline
Multiple components can form a pipeline when the output of one component is cascaded to the subsequent component as input. Pipeline is very common is most video analytics systems. For instance, in a typical event detection system, the first component extracts the foreground regions which are cascaded to the feature extraction component as input. Extracted features are then cascaded to the event detection component and so on.
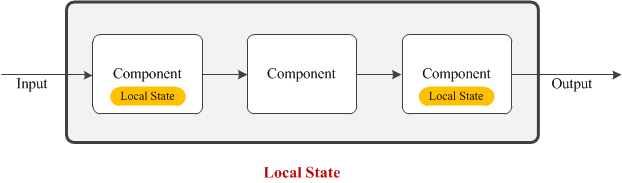
Local State
Not all processing tasks in a component can be performed by observing a single frame only. To produce the desired output these processing tasks need to observe the dynamics of consecutive video frames. To achieve this, components need to maintain some local data. For instance, a foreground detection component needs a local state or model to maintain the background model. The component might use the first observed frame to initialize the background model. Then as new frames are observed, the background model is updated. Overtime the background adapts itself with the operating environment and produces the best possible detection result.
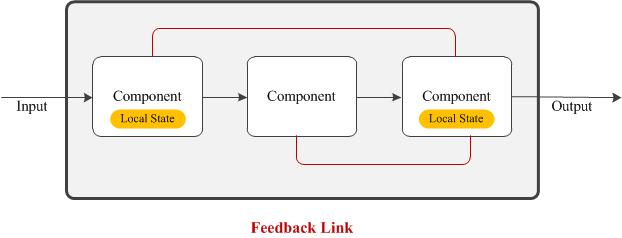
Feedback Link
Both forward and backward feedback links between two components help them synchronize their processing tasks. Sometimes the ultimate output produced by the final component is used by the initial processing components to adjust its output with the processing of the next frame (backward link). Also, some side information from the earlier processing components might help subsequent components to fine tune their outputs.
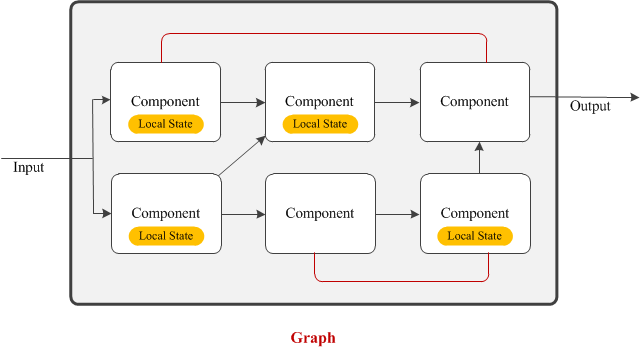
Graph
In complex systems, a simple pipeline may not be sufficient and to reuse resources, the output of one component might be consumed by multiple components. Therefore, the dependency among the components might take the shape of a graph.
Global State
Global state represents the data that can be shared by all components within the system. Global state is very useful for maintaining static information such as system parameters or any runtime information generated by the components to synchronize the overall analytics goal.

Module
A module is an independent group of processing components. The components within a module do not interact with the outside world. However, similar to a component, a module can consume multiple inputs and generate multiple outputs.
2 Comments
Pingback:
Pingback: